Многопоточное двоичное дерево - Википедия - Threaded binary tree
Эта статья может потребоваться переписан соответствовать требованиям Википедии стандарты качества. (Октябрь 2011 г.) |

В вычисление, а многопоточное двоичное дерево это двоичное дерево вариант, который облегчает обход в определенном порядке (часто тот же порядок, который уже определен для дерева).
Все двоичное дерево сортировки можно легко пройти в порядке основного ключа, но с учетом только указатель к узлу, поиск следующего узла может быть медленным или невозможным. Например, листовые узлы по определению не имеют потомков, поэтому ни один другой узел не может быть достигнут при наличии только указателя на листовой узел - конечно, который включает желаемый «следующий» узел. Многопоточное дерево добавляет дополнительную информацию в некоторые или все узлы, поэтому «следующий» узел может быть найден быстро. Его также можно пройти без рекурсии и без дополнительной памяти (пропорциональной глубине дерева), которая требуется.
Определение
Многопоточное двоичное дерево определяется следующим образом:
"Бинарное дерево резьбовой путем создания всех правильных дочерних указателей, которые обычно были бы нулевыми, указывающими на последовательного преемника узла (если он существует), и все левые дочерние указатели, которые обычно были бы нулевыми, указывают на упорядоченного предшественника узла ».[1]
Это определение предполагает, что порядок обхода такой же, как и чтобы обход дерева. Однако указатели можно вместо (или дополнительно) добавлять к узлам дерева, а не заменять связанные списки определенные таким образом также обычно называются «потоками» и могут использоваться для обеспечения возможности обхода в любом желаемом порядке (ах). Например, дерево, узлы которого представляют информацию о людях, может быть отсортировано по имени, но иметь дополнительные потоки, позволяющие быстро перемещаться по дате рождения, весу или любой другой известной характеристике.
Мотивация
Деревья, в том числе (но не ограничиваясь ими) деревья двоичного поиска, можно использовать для хранения элементов в определенном порядке, например значения некоторого свойства, хранящегося в каждом узле, часто называемого ключ. Одна полезная операция с таким деревом: обход: просмотр всех пунктов в порядке ключа.
Простой рекурсивный алгоритм обхода, который посещает каждый узел двоичное дерево поиска следующее. Предполагать т указатель на узел, или ноль. «В гостях» т может означать выполнение любого действия на узле т или его содержимое.
Алгоритм обхода (т):
- Ввод: указатель т к узлу (или ноль)
- Если т = ноль, возвращаться.
- Еще:
- траверс (левый дочерний (т))
- Посещение т
- траверс (правый ребенок (т))
Одна из проблем этого алгоритма заключается в том, что из-за его рекурсии он использует пространство стека, пропорциональное высоте дерева. Если дерево достаточно сбалансировано, это составляет О(бревно п) место для дерева, содержащего п элементы. В худшем случае, когда дерево приобретает вид цепь, высота дерева п поэтому алгоритм принимает О(п) Космос. Вторая проблема заключается в том, что все обходы должны начинаться с корня, если узлы имеют указатели только на своих дочерних узлов. Обычно имеется указатель на конкретный узел, но этого недостаточно для возврата к остальной части дерева, если не добавлена дополнительная информация, например указатели потоков.
В этом подходе может быть невозможно определить, действительно ли левый и / или правый указатели в данном узле указывают на дочерние элементы или являются следствием многопоточности. Если различение необходимо, для его записи достаточно добавить по одному биту к каждому узлу.
В учебнике 1968 г. Дональд Кнут спросил, существует ли нерекурсивный алгоритм обхода по порядку, который не использует стек и оставляет дерево неизмененным.[2] Одним из решений этой проблемы является распараллеливание дерева, представленное Дж. Х. Моррис в 1979 г.[3][4]В следующем выпуске 1969 г.[5] Кнут приписал представление дерева с нитями Perlis и Торнтон (1960).[6]
Связь с родительскими указателями
Другой способ достичь аналогичных целей - включить в каждый узел указатель на родительский узел этого узла. При этом «следующий» узел всегда доступен. "правильные" указатели по-прежнему равны нулю, если нет правильных потомков. Чтобы найти «следующий» узел от узла, правый указатель которого равен нулю, пройдите через «родительские» указатели до тех пор, пока не дойдете до узла, правый указатель которого не равен нулю и не является потомком, из которого вы только что вышли. Этот узел является «следующим» узлом, а после него идут его потомки справа.
Также возможно обнаружить родителя узла из многопоточного двоичного дерева без явного использования родительских указателей или стека, хотя это медленнее. Чтобы убедиться в этом, рассмотрим узел k с правильным ребенком р. Затем левый указатель р должен быть либо дочерним элементом, либо потоком обратно в k. В случае, если р имеет левый дочерний элемент, этот левый дочерний элемент должен, в свою очередь, иметь либо собственный левый дочерний элемент, либо поток, возвращающийся к k, и так далее для всех последующих левых детей. Итак, следуя цепочке левых указателей из р, мы в конечном итоге найдем нить, указывающую на k. Симметрично аналогична ситуация, когда q левый ребенок п- мы можем следовать q 's правые дети к нити, указывающей вперед на п.
Типы многопоточных двоичных деревьев
- Однопоточный: каждый узел направлен к либо в порядке предшественник или же преемник (левый или же верно).
- Двойная резьба: каждый узел направлен навстречу обе в порядке предшественник и преемник (левый и верно).
В Python:
def родитель(узел): если узел является узел.дерево.корень: возвращаться Никто еще: Икс = узел у = узел пока Истинный: если is_thread(у): п = у.верно если п является Никто или же п.оставили является нет узел: п = Икс пока нет is_thread(п.оставили): п = п.оставили п = п.оставили возвращаться п Элиф is_thread(Икс): п = Икс.оставили если п является Никто или же п.верно является нет узел: п = у пока нет is_thread(п.верно): п = п.верно п = п.верно возвращаться п Икс = Икс.оставили у = у.верноМассив обхода по порядку
Потоки - это ссылки на предшественников и потомков узла в соответствии с обходом по порядку.
Чтобы обход дерева с резьбой A, B, C, D, E, F, G, H, I, предшественник E является D, преемник E является F.

Пример

Давайте сделаем многопоточное двоичное дерево из обычного двоичного дерева:
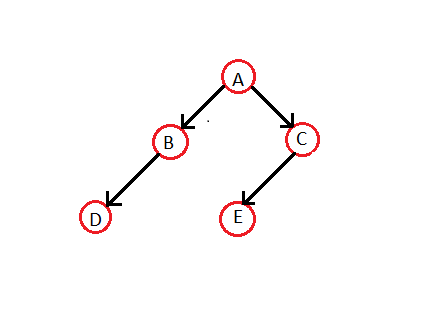
В чтобы обход для приведенного выше дерева - D B A E C. Итак, соответствующее многопоточное двоичное дерево будет -

Нулевая ссылка
В многопоточном двоичном дереве с п узлов, есть п * м - (п-1) недействительные ссылки.
Нерекурсивный обход по порядку для многопоточного двоичного дерева
Поскольку это нерекурсивный метод обхода, он должен быть итеративной процедурой; Это означает, что все шаги для обхода узла должны выполняться в цикле, чтобы то же самое можно было применить ко всем узлам в дереве.
Мы рассмотрим ЧТОБЫ обход снова. Здесь для каждого узла мы сначала посетим левое поддерево (если оно существует) (если и только если мы не посещали его ранее); затем мы посещаем (т.е. печатаем его значение, в нашем случае) сам узел, а затем правое поддерево (если оно существует). Если правого поддерева нет, мы проверяем наличие многопоточной ссылки и делаем узел с резьбой текущим рассматриваемым узлом. Пожалуйста, следуйте примеру, приведенному ниже.
Алгоритм
- Шаг 1: Для текущего узла проверьте, есть ли у него левый дочерний элемент, которого нет в списке посещенных. Если это так, перейдите к шагу 2 или шагу 3.
- Шаг 2: Поместите этот левый дочерний элемент в список посещенных узлов и сделайте его текущим узлом. Перейти к шагу 6
- Шаг 3: Распечатайте узел и, если у узла есть правильный дочерний элемент, перейдите к шагу 4, иначе перейдите к шагу 5
- Шаг 4: Сделайте правого потомка текущим узлом. Переходите к шагу 6.
- Шаг 5: Если есть узел потока, сделайте его текущим узлом.
- Шаг 6: Если все узлы были напечатаны, КОНЕЦ, иначе переходите к шагу 1
| Ли | ||||
|---|---|---|---|---|
| шаг 1 | У 'A' есть левый дочерний элемент, то есть B, который не был посещен. Итак, мы помещаем B в наш «список посещенных узлов», и B становится нашим текущим рассматриваемым узлом. | B | ||
| шаг 2 | «B» также имеет левый дочерний элемент «D», которого нет в нашем списке посещенных узлов. Итак, мы добавляем «D» в этот список и рассматриваем его как текущий узел. | B D | ||
| шаг 3 | У «D» нет левого потомка, поэтому мы печатаем «D». Затем мы проверяем его правого ребенка. «D» не имеет правого потомка, поэтому мы проверяем его ссылку на поток. У него есть поток, идущий до узла «B». Итак, мы делаем «B» нашим текущим рассматриваемым узлом. | B D | D | |
| шаг-4 | У «B» определенно есть левый дочерний элемент, но он уже в нашем списке посещенных узлов. Итак, печатаем "B". Затем мы проверяем его правого дочернего элемента, но его не существует. Итак, мы делаем его многопоточным узлом (то есть 'A') в качестве текущего рассматриваемого узла. | B D | D B | |
| шаг-5 | «A» имеет левый дочерний элемент «B», но он уже присутствует в списке посещенных узлов. Итак, печатаем «А». Затем мы проверяем его правого ребенка. «A» имеет правильный дочерний элемент «C», и его нет в нашем списке посещенных узлов. Итак, мы добавляем его в этот список и рассматриваем как текущий узел. | B D C | D B A | |
| шаг-6 | «C» имеет «E» в качестве левого дочернего элемента, и его даже нет в нашем списке посещенных узлов. Итак, мы добавляем его в этот список и рассматриваем как текущий узел. | B D C E | D B A | |
| шаг-7 | и наконец..... | Г Б А Е В |
Рекомендации
- ^ Ван Вик, Кристофер Дж. Структуры данных и программы на C, Аддисон-Уэсли, 1988, стр. 175. ISBN 978-0-201-16116-8.
- ^ Кнут, Д. (1968). Фундаментальные алгоритмы. Искусство программирования. 1 (1-е изд.). Чтение / MA: Эддисон Уэсли.
- ^ Моррис, Джозеф Х. (1979). «Простой и дешевый обход бинарных деревьев». Письма об обработке информации. 9 (5). Дои:10.1016/0020-0190(79)90068-1.
- ^ Матети, Прабхакер; Мангирмалани, Рави (1988). «Пересмотрен алгоритм обхода дерева Морриса». Наука компьютерного программирования. 11: 29–43. Дои:10.1016/0167-6423(88)90063-9.
- ^ Кнут, Д. (1969). Фундаментальные алгоритмы. Искусство программирования. 1 (2-е изд.). Эддисон Уэсли. Hre: Раздел 2.3.1 «Обход двоичных деревьев».
- ^ Перлис, Алан Джей; Торнтон, К. (апрель 1960 г.). «Манипулирование символами с помощью многопоточных списков». Коммуникации ACM. 3 (4): 195–204. Дои:10.1145/367177.367202.